Documentation Overview#
This documentation provides an overview of the Dictionary LSP to Spanish and guides you through the process of getting started with using the system. It outlines the necessary requirements, the overall structure of the Dictionary LSP to Spanish, and the workflow involved in building the system effectively.
Prerequisites for Developers#
This documentation is designed to facilitate developers in continuing or replicating the Dictionary LSP project. To get started, ensure the following prerequisites are met:
Hardware and Connectivity: Access to a computer with an internet connection is essential for project development and replication.
AWS CLI and Credentials: Install the AWS Command Line Interface (CLI) on your local machine and configure the project AWS credentials.
Python Environment: Set up Python on your local machine or within virtual environments as per the specific library requirements detailed in each development step.
Optional: MLOps and AWS Experience: While not mandatory, prior familiarity with MLOps practices and AWS services can greatly facilitate project development and understanding.
Optional: Deep Learning and Transformers Experience: Experience in deep learning, particularly with Transformers, is advantageous for certain aspects of the project.
Overview of the Dictionary LSP to Spanish#
The Dictionary LSP to Spanish is a comprehensive resource that facilitates the translation of terms and phrases from Peruvian Sign Language (LSP) to Spanish. It provides a rich glossary of signs, including videos, translations, sign language transcriptions, and example sentences for each term. The Dictionary LSP to Spanish serves as a valuable tool for learning LSP and bridging the communication gap between the deaf community and Spanish speakers.
Overview of the Workflow#
The workflow to build a Dictionary LSP required two main modules: Model Building and Deployment
Model Building Workflow#
The model building workflow consists of training a Sign Language Recognition (SLR) model with the primary task of interpreting the signs performed in the search for signs in the LSP dictionary (Sign Language to Spanish). To achieve this, a preprocessed and properly prepared database is essential to feed the SLR model. The database underwent a series of steps for video preparation and annotation, data preparation based on landmarks, and finally, the training of a Transformer-based model known as SPOTER.
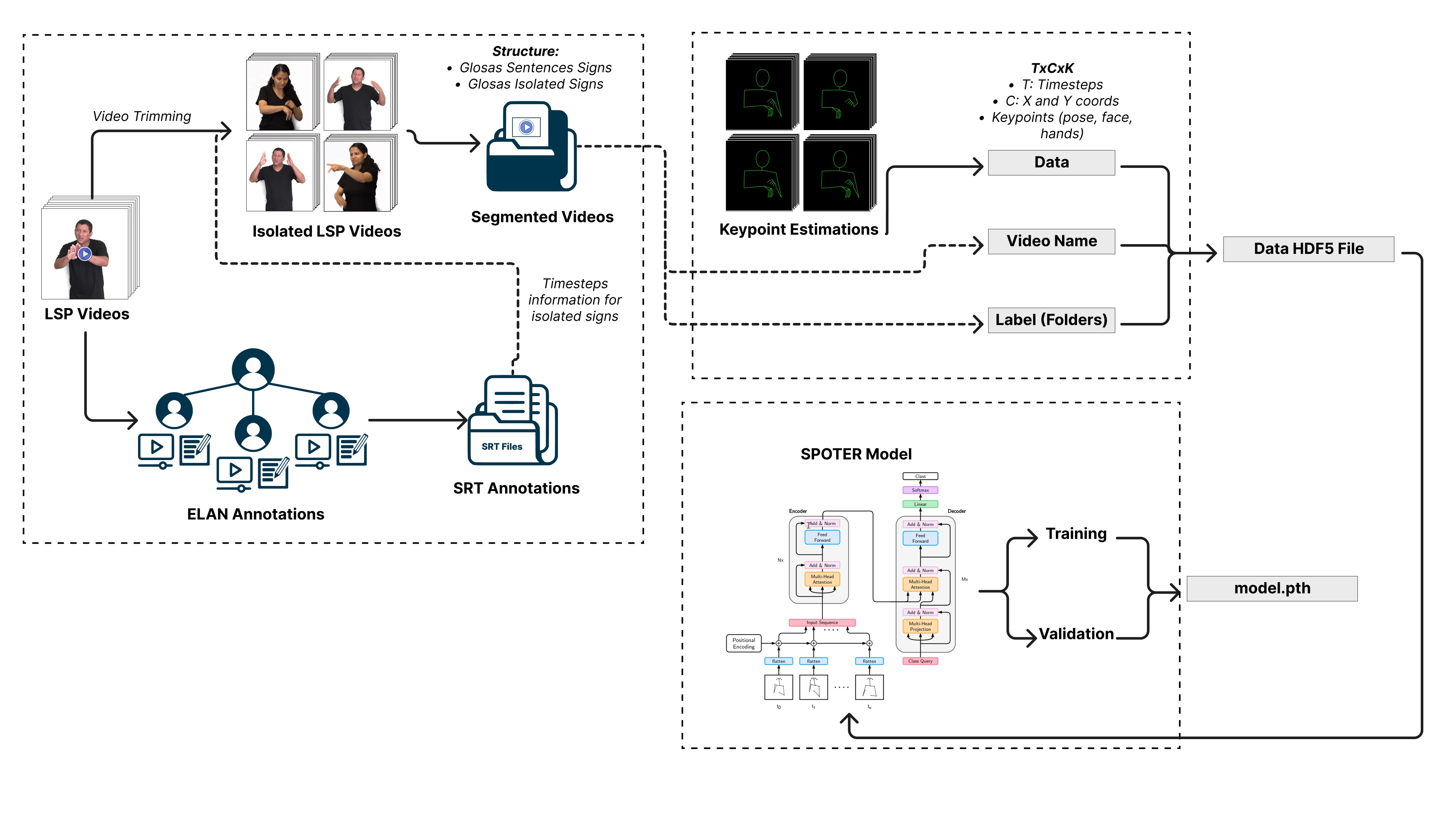
Model Deployment Workflow#
Building upon the trained model, the deployment of this model into production requires two elements from the previous process: the model.pth file and the segmented videos (isolated sign videos and sentence videos). This stage consists of two parts.
Part 1: Inference for Sign Search Production
For the deployment of sign search functionality, we utilize the AWS Sagemaker services and S3 buckets. Leveraging the power of Sagemaker, we perform inference to enable seamless sign language searches within the application. The isolated sign videos and sentences are processed to extract meaningful information, allowing users to easily search for sign language translations.
Part 2: Text-Based Search
In addition to sign-based searches, we also support text-based searches using both S3 and DynamoDB as No-SQL tables. This enables efficient storage and retrieval of relevant data for text-based queries. Leveraging AWS Lambda functions, we efficiently manage the initialization and execution of each part of the search process, providing a seamless and responsive experience for users based on their specific needs and preferences.
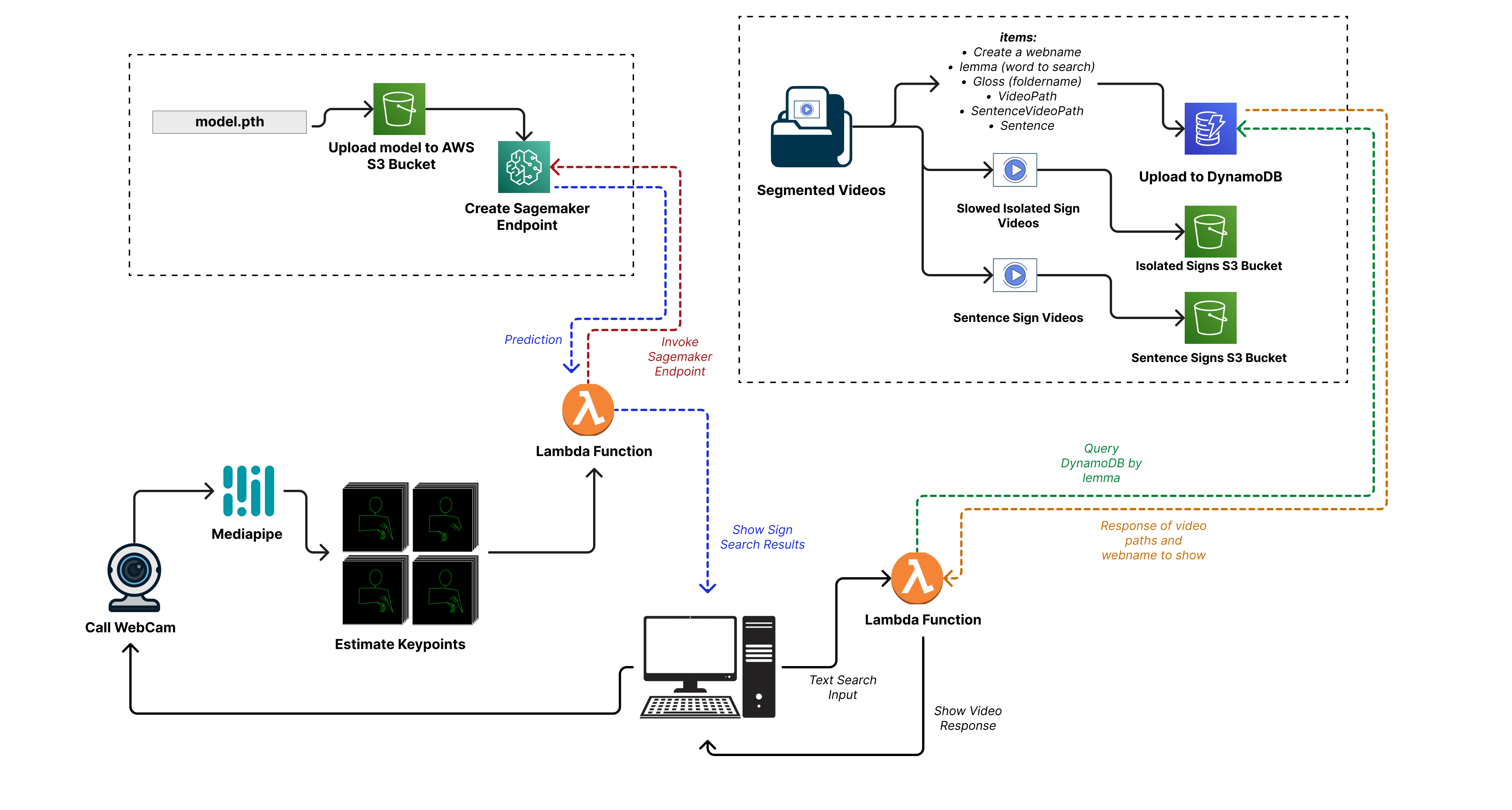
Throughout this documentation, we will provide detailed instructions and explanations for each step of the workflow, enabling you to make the most of the Dictionary LSP to Spanish and effectively engage with the LSP language and community.