Model Deployment and Inference#
Model deployment and inference are the core module for the Sign Search funcionality. This documentation provides an initial understanding of these processes, while detailed instructions and code can be found in the Inference repository.
Model Deployment Process#
Clone the Diccionario LSP repository to your local machine.
Prepare the
model_inference_formatfolders.Run
deploy.py. This script automates the deployment of the Sagemaker endpoint and creates the Docker image required for the EC2 deployment.Use a AWS Lambda function to test the deployed model in AWS platform.
In the context of the Dictionary LSP, we have prepared a Python file called deploy.py to deploy the “Spoter” model using AWS Sagemaker. More details of prerequisites and the steps to set the inference in production is available in the Diccionario LSP repository
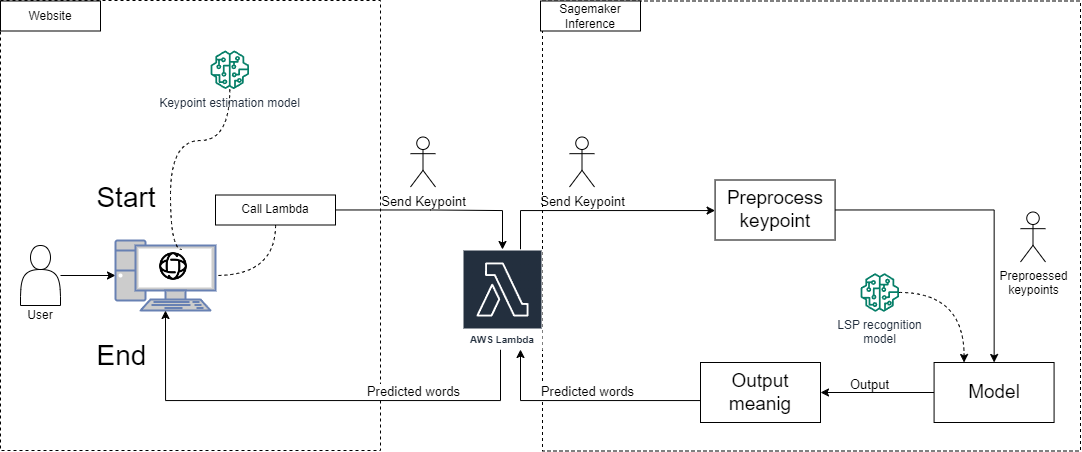
The diagram show how the inference works in the deployment process
IMPORTANT The file “inference.py” have to have necessary functions:
def input_fn(request_body, request_content_type):
def predict_fn(input_data, model):
def model_fn(model_dir):
def output_fn(prediction, content_type):
Remember to modify the configuration json file located in “configuration” folder (in root folder) –>
General overview of the model we use#