Sign Language Recognition Model Overview#
For the SLR model training stage, a pre-existing model developed by Matyáš Boháček and Marek Hrúz from the SPOTER repository was used as a starting point. However, several modifications were made to adapt the model to the specific dataset being worked on.
The following files were modified:
Lsp_dataset.py: The keypoints were adapted to the output provided by Mediapipe. This adaptation was done from the data loading in Connecting Points to the data output. Although it is uncertain whether the same keypoints as SPOTER were used, the data augmentation structure remains the same as in SPOTER, but it was adjusted to work with the appropriate keypoints from Mediapipe.body_normalization.pyandhand_normalization.py: The structure of these files remains similar to SPOTER, but the keypoints were adjusted to work with Mediapipe. The normalization was changed from using the neck distance to using the shoulder distance, which may require further review. However, it should be noted that there are studies showing that normalizing by either neck distance or shoulder distance is acceptable.utils.py: Adapted to work with WandB and adjusted to meet the specific reporting needs of the project.spoter_model.py: The SPOTER model has undergone several changes, but in the latest version, it was made to closely resemble the original. The only variations made were related to the hyperparameters.train.py: This file has undergone significant changes and essentially represents a custom implementation, building on the work of SPOTER as a foundation.
Finally, model.pth is saved to be used in the inference as part of the deployment step
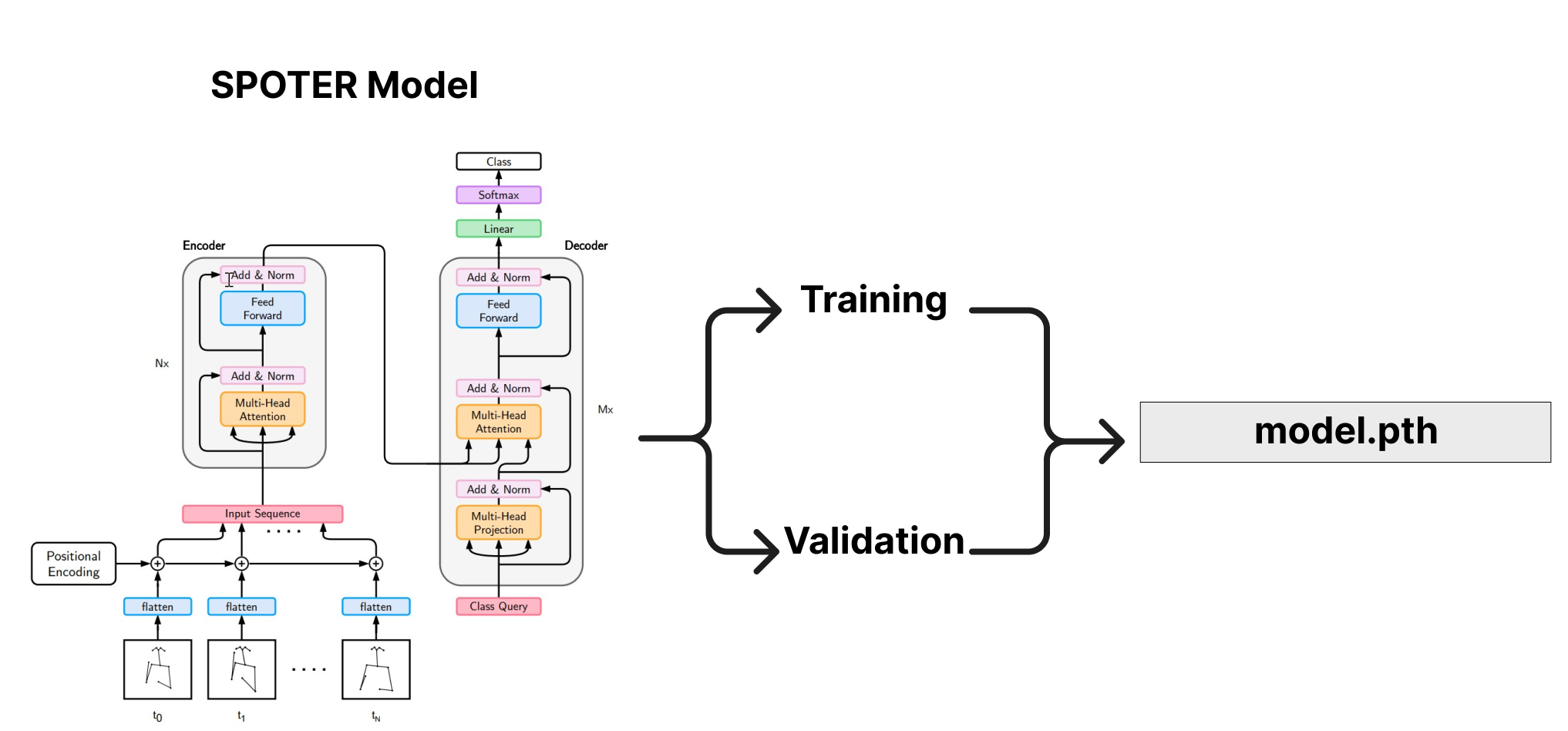
It is important to note that while the SLR model is based on the SPOTER repository, the modifications and adaptations mentioned above were essential to ensure its suitability for the specific sign language dataset being used in the project. Details about the implementation of our adaptation of SPOTER model is in the Spoter-LSP-IA-Model repository.